




精神医療におけるLLM(大規模言語モデル)活用が現実味を帯びる一方で、「その応答は本当に臨床的に妥当で安全なのか?」という問いは未解決のまま残されてきました。
2026年、この課題に正面から挑む新たな評価ベンチマーク「PsychiatryBench」が npj Digital Medicine にて公開されました。
本記事では、5,188項目・11タスクで構成される本ベンチマークの全容と、精神科医・心理職が押さえておくべき臨床的示唆を整理します。
PsychiatryBenchとは?なぜ今このベンチマークが必要なのか
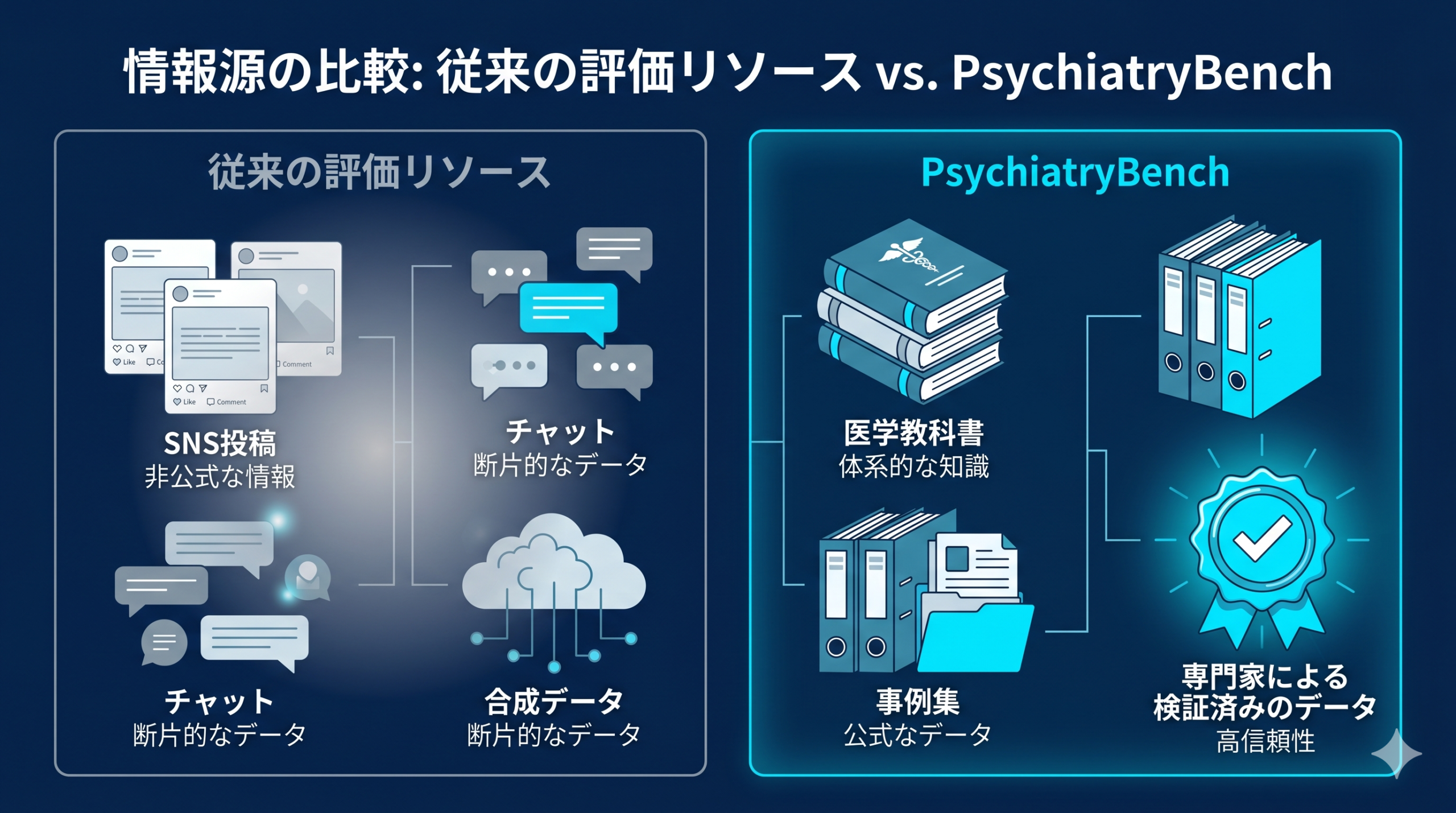
PsychiatryBenchは「精神医学の教科書および症例集のみを情報源として、LLMの臨床推論能力を11タスク・5,188項目で評価する多面的ベンチマーク」です。
これまでのメンタルヘルス領域のLLM評価は、臨床面接の転写データ、SNSの自由記述投稿、合成対話データなど、臨床的信頼性の揺らぐ情報源に依存してきました。
つまり、評価基盤そのものが「診断判断や治療方針の妥当性を厳密に測定するには精度不足」という構造的課題を抱えていたのです。
PsychiatryBenchは、この問題を抜本的に是正します。
情報源は専門家が検証した教科書と症例集に限定されています。
たとえば、匿名SNSから学習した「共感風応答」ではなく、精神医学教育の現場で実際に用いられる症例シナリオを解く能力そのものを測定できる設計になっています。
11のタスクで何を評価するのか?
PsychiatryBenchは、精神科臨床の推論プロセスを11種類の質問応答タスクに分解しています。
代表的なタスクは以下の通りです。
- 診断推論(Diagnostic Reasoning)
- 治療計画(Treatment Planning)
- 長期フォローアップ(Longitudinal Follow-up)
- 管理計画(Management Planning)
- 臨床アプローチ(Clinical Approach)
- 逐次症例分析(Sequential Case Analysis)
- 多肢選択問題・EMQ形式(Multiple Choice / Extended Matching)
- その他、症例説明・鑑別解説タスク
特に注目すべきは、「単発の一問一答」ではなく、逐次症例分析や長期フォローアップといった多段階・時間軸を含むタスクが評価対象に据えられている点です。
これは臨床推論の本質である「経過とともに仮説を修正し、方針を再構築する思考プロセス」を問う設計であり、従来の医療系LLMベンチマークでは十分に扱われてこなかった領域です。
主要モデルの評価結果で何が分かったのか?
研究チームは、Google Gemini、DeepSeek、Claude Sonnet 4.5、GPT-5 等の汎用フロンティアLLMに加え、MedGemma のような医療特化型オープンソースモデルも対象に評価を行いました。
評価は従来の定量指標に加え、LLM-as-judgeによる類似度スコアリングを組み合わせたハイブリッド方式です。
| タスク種別 | 得意領域 | 課題が残る領域 |
|---|---|---|
| 単発QA(MCQ/EMQ) | 比較的高い正答率を示す | — |
| 多段階フォローアップ | 初回判断は妥当なケースあり | 経過に応じた方針修正の一貫性が崩れる |
| 管理計画 | 教科書的対応の列挙は可能 | 長期的ケア設計の安全性・整合性に不足 |
つまり、「診断名を当てる」ことと「患者を長期的に管理する」ことの間には、現在のLLMにとって決して小さくない壁が存在するわけです。
特に多段階フォローアップや管理計画といった領域で、臨床的一貫性および安全性に実質的なギャップがあることが定量的に示された意義は大きいと言えます。
精神科医・心理職が押さえるべき臨床的示唆
本研究は、LLMを精神医療の実務に組み込む際に押さえておくべき3つの原則を示唆しています。
1.専門ドメイン調整の必要性
汎用LLMをそのまま臨床判断に用いるのはリスクが高く、精神医学コーパスによる追加チューニングが前提となる。
2.多段階タスクを含む評価基準の採用
単発QAではなく、経過観察・再評価・継続管理を含む評価フレームで自施設用途の適合性を検証する。
3.ヒューマン・イン・ザ・ループの徹底
臨床判断の最終責任は臨床家にあり、LLMは意思決定支援ツールとして位置付ける。
精神医療は、患者の語りと文脈を長期的に紡ぎ続ける営みです。
PsychiatryBenchが可視化した「長期フォローアップにおけるLLMの脆さ」は、逆説的に、臨床家の継続的関与の価値を定量的に裏付けたとも言えます。
まとめ:AI×メンタルヘルスケアの新たな標準へ
- PsychiatryBenchは教科書・症例集のみを情報源とする、信頼性の高い精神医学LLM評価ベンチマーク。
- 5,188項目・11タスクで診断推論から長期フォローアップまで網羅。
- 主要LLMは多段階タスクにおいて臨床的一貫性・安全性に課題を残す。
- 精神医学領域でのLLM活用には、専門ドメイン調整と継続的評価が不可欠。
- 次のステップは、自施設ワークフローでLLMが補完すべき工程と人が優先すべき判断の明確化。
精神医療におけるLLM活用は、「万能の相談相手」ではなく「専門家を支援する臨床ツール」として設計される段階へと移行しています。
PsychiatryBenchは、その議論のための共通言語となるベンチマークです。
【出典】
PsychiatryBench: a multi-task benchmark for LLMs in psychiatry | npj Digital Medicine
【あわせて読みたい】
















コメントを残す