




「何度も繰り返し練習すれば、いずれ身につく。」
そう信じてきた方は多いのではないでしょうか?
実はこの「当たり前」が、最新の脳科学研究で根本から揺さぶられています。
『Nature Neuroscience』に掲載された研究によると、脳が学習するスピードを決めるのは「経験の回数」ではなく、報酬と報酬の間の時間間隔だったのです。
この記事では、パブロフ学習の新常識から、教育や日常生活への応用まで、わかりやすく徹底解説します。
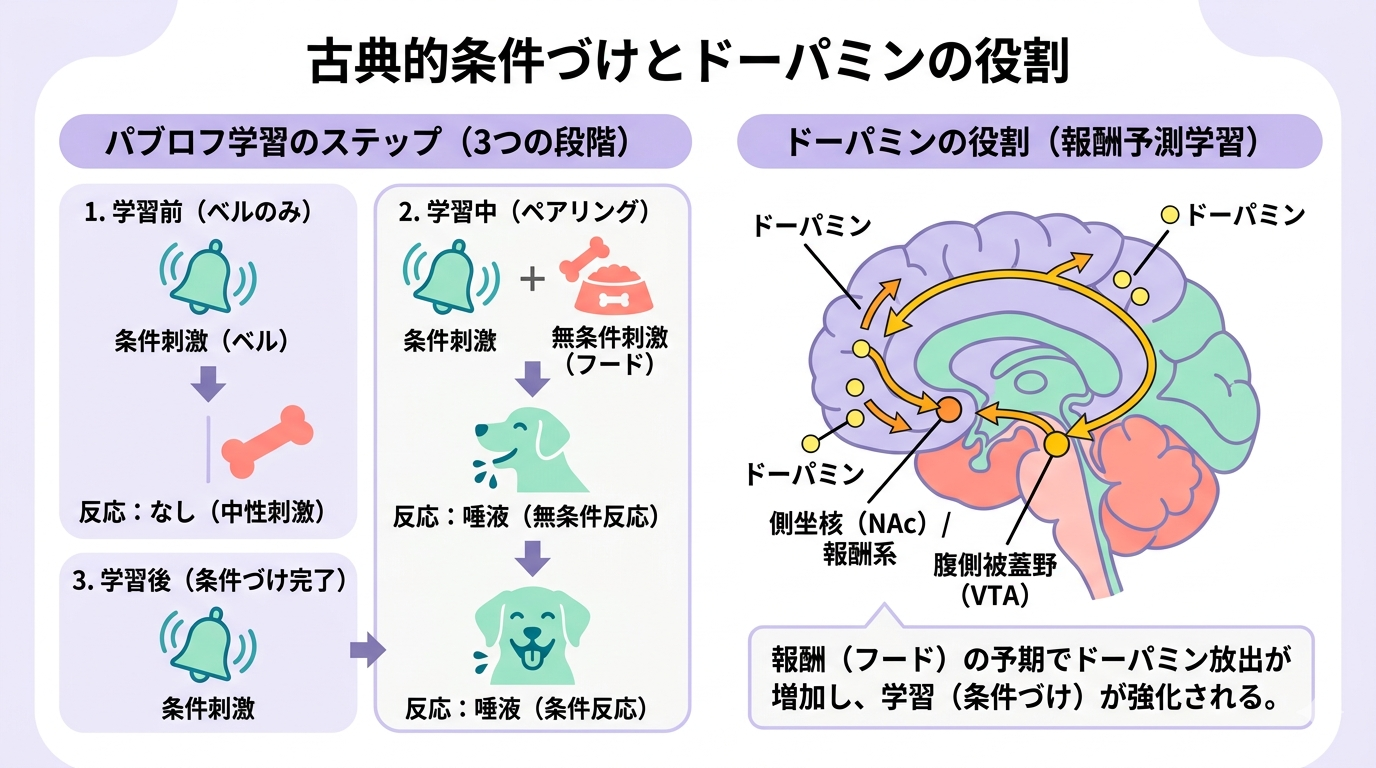
そもそもパブロフ学習(古典的条件づけ)とは?
パブロフ学習(古典的条件づけ)とは、もともと関係のない刺激(ベルの音など)と、自然に反応を引き起こす刺激(食べ物など)を繰り返しペアにすることで、新たな反応を学習する仕組みのことです。
パブロフの犬の実験をおさらい
1890年代、ロシアの生理学者イワン・パブロフは、犬を使った有名な実験を行いました。
| ステップ | 刺激 | 犬の反応 |
|---|---|---|
| 学習前 | ベルの音だけ | 唾液は出ない |
| 学習前 | 食べ物を見せる | 唾液が出る(自然な反応) |
| 学習中 | ベルの音 → 食べ物を繰り返しペアで提示 | ベルと食べ物を結びつけ始める |
| 学習後 | ベルの音だけ | 唾液が出る(学習された反応) |
この実験以来、「信号(ベル)と報酬(食べ物)をペアで繰り返し経験すれば学習が進む」というのが科学界の常識でした。
つまり、回数こそが学習のカギだと約1世紀にわたって信じられてきたのです。
ドーパミンの役割
学習において重要な脳内物質がドーパミンです。
ドーパミンとは、脳の報酬系で中心的な役割を果たす神経伝達物質のこと。何か良いこと(報酬)が起こると放出され、「この行動をまた繰り返そう」という学習信号として機能します。
特に注目されるのが**報酬予測誤差(Reward Prediction Error: RPE)**という概念です。これは「予想していた報酬」と「実際に得られた報酬」の差のことで、この差が大きいほどドーパミンが多く放出され、学習が促進されると考えられてきました。
【あわせて読みたい】

新研究が明かした衝撃の事実!カギは「回数」ではなく「時間間隔」だった
従来の常識 vs 新発見
『Nature Neuroscience』に掲載されたこの研究は、パブロフ学習に関する根本的な前提をひっくり返しました。
| 項目 | 従来の理解 | 新研究の発見 |
|---|---|---|
| 学習を決める主な要因 | 信号と報酬をペアで経験した回数 | 報酬と報酬の間の時間間隔 |
| 学習速度の変化 | 試行回数に比例して変化 | 報酬間の時間間隔に比例して変化 |
| ドーパミン反応 | 試行回数に連動 | 報酬間の時間間隔に連動 |
| 理論的フレームワーク | 試行ベースの強化学習モデル | 時間ベースの学習モデル |
どういうことかを具体的に言うと?
たとえば、あなたがコーヒーショップで毎回ポイントスタンプをもらうとしましょう。
従来の考え方
10回通えば「コーヒーショップ=ポイントがもらえる」と学習する。回数が大事。
新しい考え方
1日おきに通った場合と、1週間おきに通った場合では、同じ10回でも学習のスピードが異なる。
報酬を多く詰め込んでも学習は加速しない。時間をかけて間隔を空けるほど、1回の経験から多くを学べる。
つまり、単に「何回経験したか」ではなく、「どれくらいの頻度で報酬を受け取ったか」が脳にとって決定的に重要だというのです。
ドーパミンも時間間隔に反応していた
研究チームは、行動の変化だけでなく、ドーパミンニューロンの反応パターンも調べました。
その結果、ドーパミン反応も行動と同じく、報酬間の時間間隔に比例して変化することが確認されました。
これは、脳の報酬学習システムそのものが「回数カウンター」ではなく、「時間計測器」のように働いている可能性を示唆しています。
よくある疑問と誤解を解消!Q&A
ここまで読んで、いくつか疑問が浮かんだ方もいるかもしれません。よくある質問にお答えします。
Q1. パブロフ学習そのものが否定されたの?
A. いいえ、否定されたわけではありません。
パブロフ学習(古典的条件づけ)のメカニズム自体は健在です。覆されたのは、「学習速度は試行回数で決まる」という前提条件の部分です。
学習そのものは起きますが、その速さを決めるルールが違った、というのが正確な理解です。
Q2. 「報酬間の時間間隔」ってもっと具体的に言うと?
A. ある報酬を受け取ってから、次に報酬を受け取るまでの時間のことです。
たとえば犬の実験なら、食べ物を与えてから次に食べ物を与えるまでの間隔です。
時間をかけて間隔を空けるほど、1回の経験から多くを学べるという事が、今回の研究から明らかになりました。
Q3. これは動物の話でしょ?人間にも当てはまるの?
A. 研究チームは、この発見が人間の学習にも適用される可能性が高いと考えています。
ドーパミンを介した報酬学習のメカニズムは、動物と人間で共通する部分が多く、教育や行動療法への応用が期待されています。
Q4. 今までの強化学習の研究は全部間違いだったの?
A. すべてが間違いというわけではありません。
ただし、試行回数ベースで設計された多くの学習モデルは、時間間隔の要素を取り入れて修正する必要があるかもしれません。
AI分野の強化学習アルゴリズムにも影響を与える可能性があります。
教育・日常・治療にどう活かせる?新発見の実践的な意味
この研究が示唆することは、学術的な話だけにとどまりません。
私たちの日常や教育、臨床の場にも大きな影響を及ぼす可能性があります。
教育・学習への応用
| 従来のアプローチ | 新研究に基づくアプローチ |
|---|---|
| 「とにかく問題を多く解け」(回数重視) | 「適切な間隔で復習せよ」(時間間隔重視) |
| 1日に50問解く | 短い間隔で10問ずつ × 複数セッション |
| 詰め込み型テスト勉強 | スペース学習(分散学習)の最適化 |
実践ポイント
- 復習の「頻度」を意識する 。
- 報酬(達成感・フィードバック)のタイミングを最適化する 。
- 間隔を段階的に調整する 。
行動療法・臨床への応用
不安障害や依存症の治療に使われるエクスポージャー療法(段階的暴露療法) にも、この発見は新たな視点を提供します。
- セッション間の間隔を最適化することで、治療効果を高められる可能性。
- 報酬スケジュールの再設計による、より効率的な行動変容プログラムの開発。
AI・強化学習への影響
AIの強化学習アルゴリズムの多くは、試行回数ベースの学習モデルに基づいています。
この研究は、時間間隔をパラメータとして組み込んだ新しいアルゴリズム設計への道を開く可能性があります。
まとめ
今回の記事のポイントを振り返りましょう。
- パブロフ学習の学習速度を決めるのは「回数」ではなく「報酬間の時間間隔」だった。
- ドーパミン反応も時間間隔に比例して変化する 。 脳の報酬システムは「時間計測器」として働いている可能性がある。
- パブロフ学習そのものは否定されていない。 覆されたのは「回数が決め手」という前提。
- 教育・治療・AIなど幅広い分野に応用の可能性 。報酬スケジュールの最適化が学習効率を劇的に向上させうる。
- 日常の学習でも「間隔」を意識することで効率アップが期待できる。 間隔反復法の科学的裏づけがさらに強化された。
【参考文献】
Neuroscientists just upended our understanding of Pavlovian learning(Nature Neuroscience)
【あわせて読みたい】














コメントを残す